Python 机器学习
模型评估、选择、验证
损失函数
0-1 损失函数
1 | from sklearn.metrics import zero_one_loss |
对数损失函数
对数损失函数是用来对概率分布模型来进行评价。概率分布模型得到的结果是对于事件预测的一个概率值。因此对数损失函数评价的是模型得到的概率分布与真实的概率分布之间的差距。因为概率模型的学习是先构建一个条件分布,然后通过最小化该概率分布得到最优的模型,因此是用对数函数来表示。
$$
Loss(y, p(y|x)) = -log(P(y|x))
$$1
2from sklearn.metrics import log_loss
loss =log_loss(y, y_pred, eps =1e-15 ,normalize=True, sample_weight)
数据集的切分
留出法
将数据集D划分为两个部分,一个作为训练集,用于对模型的训练;一个作为测试集,用于对模型的测试。
训练测试的划分需要考虑到数据分布的一致性,要保持样本类比比例的一致。
模型评估的过程往往是对数据集进行多次的分割,每次计算模型的精度,然后取一个平均值来作为模型最后的结果。1
2from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size,train_size,random_state)
交叉验证法
将原有的测试集分成k个大小相同的不重叠的组。每次用k-1个组作为训练集,剩余的1个组作为测试集,进行k次的训练和测试,最终的结果是这k次结果的平均值。1
2
3
4
5
6
7
8from sklearn.model_selection import KFold
#KFold是一个生成器,用来在建模的过程中,循环生成数据集
folder = KFold(n_splits=3,random_state=0,shuffle=False)
for train_index,test_index in folder.split(X,y):
print("Train Index:",train_index)
print("Test Index:",test_index)
print("X_train:",X[train_index])
print("X_test:",X[test_index])
通常来说,要进行p次的分组,用的是p次分组的k折交叉验证的平均值,常见的有10次10折交叉验证方法。在sklearn里面,RepeatedKFold用来实现。1
2
3from sklearn.model_selection import KFold
rkf = RepeatedKFold(n_splits=10, n_repeats=10, random_state=random_state)
#n_repeats表示重复的次数
考虑到样本数据集分布的特征,在进行数据集交叉验证的分割时,也可以用分层的K折交叉法,在Python中是引用的StratifiedKFold,具体用法与KFold类似。1
from sklearn.model_selection import StratifiedKFold
使用交叉验证最简单的方法是在估计器和数据集上调用 cross_val_score 辅助函数1
2
3from sklearn.model_selection import cross_val_score
clf = svm.SVC(kernel='linear', C=1)
scores = cross_val_score(clf, iris.data, iris.target, cv=5)
自助法
Bootstraping Method 是一种重抽样方法。适合于小样本数据集
性能的度量
错误率和精度的定义
$$
E(f;D)= \frac{1}{m}\sum^{m}_{i=1}I(f(x_i) \ne yi)
$$
$$
acc(f;D) = 1 - E(f;D)
$$
对于更一般的形式,给定了数据分布D和概率密度函数$$$p(x)$$$
==如何理解更一般的形式?==
$$
E(f;D)= \int{x\sim D}I(f(x_i)\ne y_i)p(x)dx
$$
在Python里面scikit-learn提供了accuracy_score函数来进行准确率的计算。1
2from sklearn.metrics import accuracy_score
score = accuracy_score(y_true,y_pred,normalize=True)
查准率、查全率与F1
- 查准率(Precision):
我预测为正例的事件,有多少是真正的正例。 - 查全率(Recall):
我预测为正例的事件,在全部正例中占多少比例。
++混淆矩阵++

1 | from sklearn.metrics import confusion_matrix |
那么查准率$$$P$$$和查全率$$$R$$$的计算方法就是:
$$
P = \frac{TP}{TP+FP}
$$
$$
R = \frac{TP}{TP+FN}
$$
查准率和查全率是相互制约的,如果差准率高,那么查全率就低,反之亦然。
1 | from sklearn.metrics import precision_score,recall_score |
P-R图就是用来衡量一个模型在样本上的查全率和查准率。P-R的绘制包括三个步骤:
- 根据学习期的预测结果对样例进行排序,预测概率越大的排在前面;
- 按照排序的顺序,一个一个的计算查准率与查全率;
- 将每一个P-R对画在坐标系中。
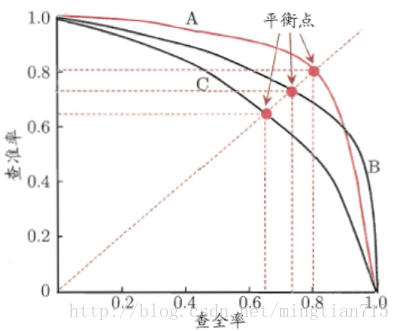
1 | from sklearn.metrics import precision_recall_curve |
通过P-R图,就可以直观来进行模型的比较。模型曲线越向右侧凸,就越好。如果两个P-R曲线有交叉,则通过平衡点(Break-Even Point)来进行评价。BEP就是45度线与P-R线的交点,越大越好。另外更常用的是F1度量。
$$
\frac{1}{F1} = \frac{1}{2}(\frac{1}{P}+\frac{1}{R}) \
F1 = \frac{2\times P\times R}{P + R}
$$
更一般的是$$$F{\beta}$$$度量
$$
\frac{1}{F_{\beta}}= \frac{1}{1+\beta^2}(\frac{1}{P}+\frac{\beta^2}{R}) \
$$
当$$$\beta>1$$$的时候,查全率更重要;当$$$\beta<1$$$的时候,查准率更重要
1 | from sklearn.metrics import f1_score, fbeta_score |
在Python中,scikit-learn包提供了classification_report函数给出分类任务结果的主要性能指标。1
2from sklearn.metrics import classification_report
classification_report(y_true,y_pred,...)
ROC与AUC
ROC的全称是Receiver Operation Characteristic
ROC的思想与P-R曲线有点类似,就是将得到的预测结果按照预测的概率进行排序,排在前面的是预测结果可能性高的,越靠后就是越不可能是正例的结果。
假设有两个模型结果进行比较,对两个模型的排序结果进行比较,就能在一定程度上表示两个模型的优劣。
ROC曲线的两个轴线分别是TPR(真正例率)和FPR(假正例率)
$$
TPR = \frac{TP}{TP+FN} \
FPR = \frac{FP}{TN+FP}
$$
AUC是ROC曲线下的面积,用来比较两个模型的优劣。AUC越大说明模型泛化性能越好。
1 | from sklearn.metrics import roc_curve |